[ICNP'21] Is Machine Learning Ready for Traffic Engineering Optimization? 阅读笔记
·25 words·1 min·
0
·
0
·
Author
Ryan
Table of Contents
论文笔记 - This article is part of a series.
Part : This Article
文章背景 #
目前的TE解决方案中,比较常见的方式是预先计算节点到节点之间的多条路径,然后在这些路径上调整分流比例。而该文章中,作者采用的方式则是与OSPF进行结合。文章提出的方法是通过强化学习 + GNN的方式来调整链路的权重,然后让OSPF按照自己的方式,根据链路权重和Dijkstra算法来计算路径。
解决方案 #
该方案中,首先使用一个GNN来提取网络的link与邻居的特征,然后再把提取到的特征送入DRL,DRL计算得到需要执行的动作。
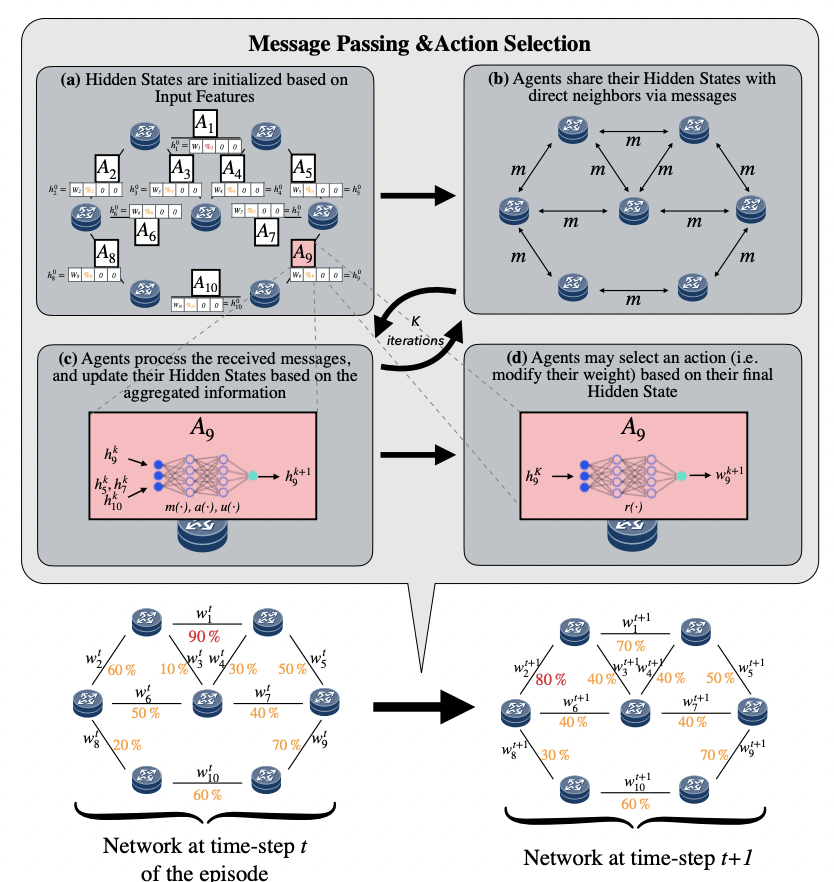
GNN #
该方案中采用的GNN是MPNN,link将自己的初始权重和链路利用率作为自己的初始hidden state,然后将自己的hidden state和邻居link交换。再将收集到的所有hidden state经过一个全连接层,再来一次逐元素相加,一个全连接层得到一个新的hidden state。重复这个步骤得到一个link最终的hidden state。
DRL #
该方案的DRL采用PPO算法,主要是将GNN输出的hidden state计算得到一个最终的概率。并以这个概率进行采样,根据采样结果来决定是将权重增加1还是减少1。可以看到DRL的结果并直接就是link的权重。
思考 #
- 感觉这个算法优点浪费计算资源,每次经过那么多的迭代就得到一个对一条link权重的增减,感觉其实可以根据提取到的特征来做更多的事情
- 原文中有将DRL计算得到的概率在agent之间共享,并且每个agent都共享相同的随机种子。按照原文的说法,这样的话每个agent都可以去采样得到相同的结果。但是我感觉这样并不是很有意义,因为采样是一个很简单的工作,结果还需要去增加共享开销
- 经过那么多的计算量,最终做的事情知识将权重增加或者减少一点点。这样会不会导致对于网络状况的反应不够迅速?例如对于突然产生的拥塞调整的太慢
论文笔记 - This article is part of a series.
Part : This Article