(INFOCOM'21)DRL-OR: Deep Reinforcement Learning-based Online Routing for Multi-type Service Requirements 阅读笔记
Table of Contents
论文笔记 - This article is part of a series.
针对的问题 #
在传统的网络路由的算法中,路由对flow的处理方式通常是基于最短的跳数或者是链路的权重来计算如何路由,但是这种方式并不能对不同类型的flow进行区别对待。在 DRL-OR文章中,作者提出了4种基本的flow的类型,如下所示。
| 服务类型 | 典型应用 |
|---|---|
| latency-sensitive | 上网 |
| throughput-sensitive | 下文件 |
| latency-throughput-sensitive | 视频直播 |
| latency-loss-sensitive | 打游戏 |
文章认为应该分别对每种类型的flow有针对性的处理,否则就会出现如下图所示的情形。
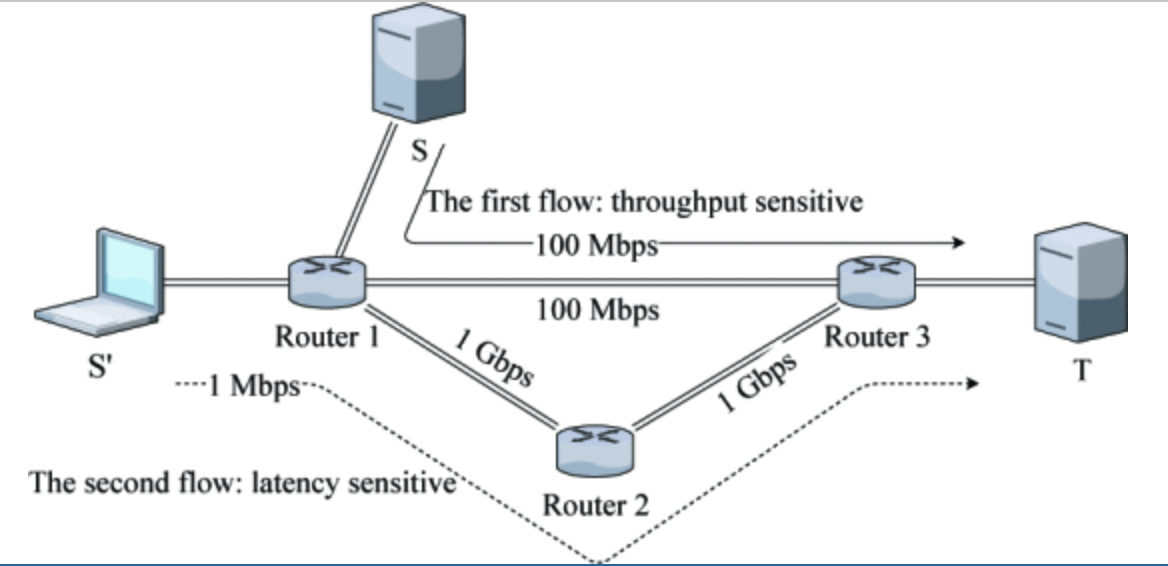
第一个flow是由S->T,它直接占据了Router1和Router3之间的所有带宽。导致第二个S’->T的latency-sensitive 的flow不得不去绕路,导致时延增加。文章希望通过深度强化学习(DRL)的方式来让AI自动学习如何去规划每个flow的路径(path)。
强化学习模型 #
文章中采用PPO算法来实现,主要是考虑到PPO比较有效率,并且训练的方差比较小,训练过程可以更加稳定。
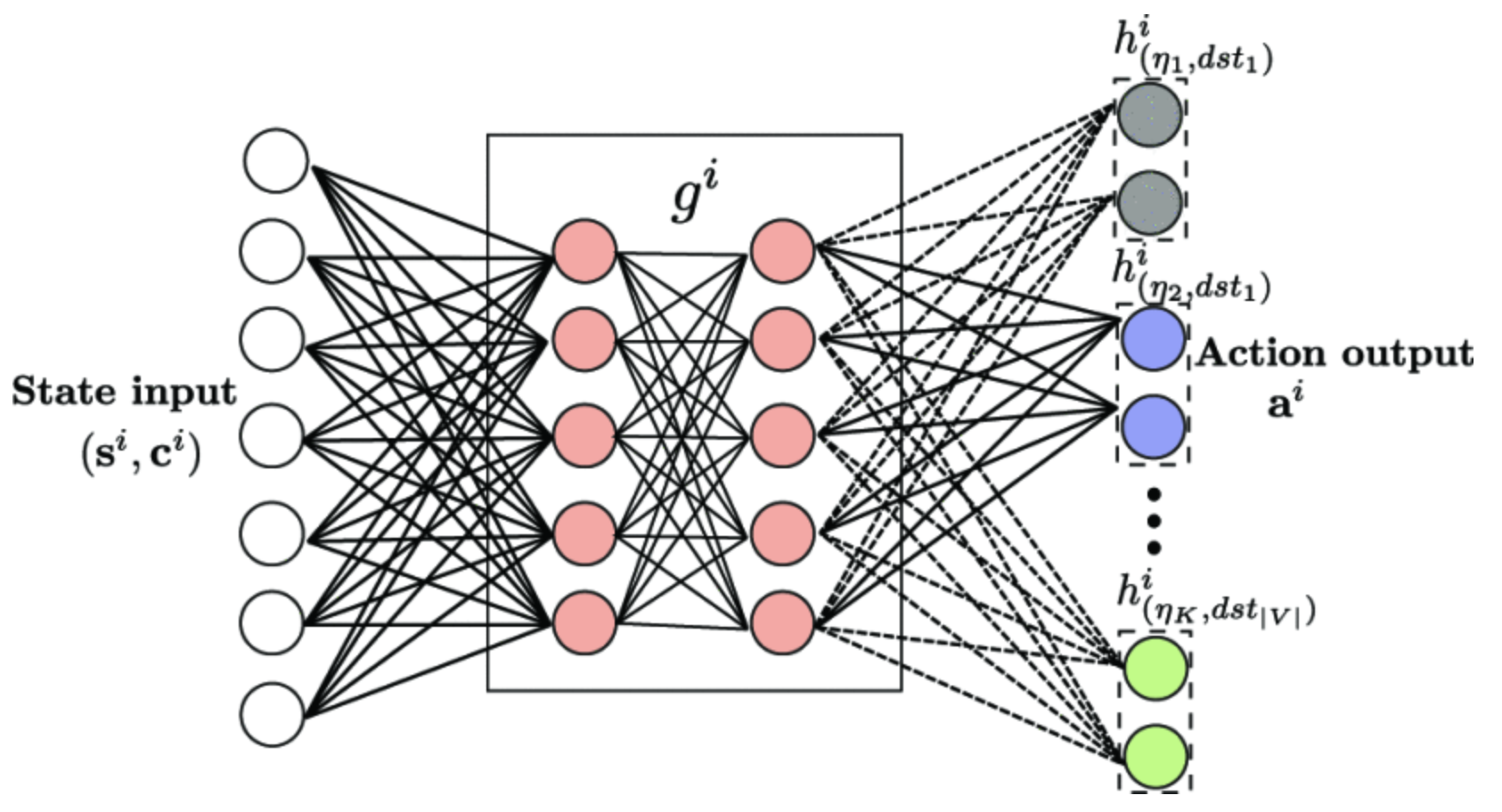
上图是文章中的神经网络,中间层是64*64的全连接层。输出层非常的特别,采用了一种非常冗余的方式,它计算了所有的目标节点,所有的服务类型,所有的action的概率。文章中给的图会有一点误导性,会让人感觉输出的神经元是全部并列在一起的,但实际上这些输出的神经元是“叠起来”的。假如有$V$个节点,有$T$个类型,有$A$个action。就会有$VT$个小网路,每个小网络都是是 $64 \cdot A$的结构(64是隐藏层的神经元个数),并且全部接在前面的隐藏层后面。
在这个网络中,action的数目就是一个节点的邻居数目,也就是转发的时候可以的选择个数。而且一个agent有一个自己的网络(上图代表的一整个网络)。
之所以采用这样冗余的做法,按照文章中作者的说法是,这样做有很好的灵活性,如果有新的节点或者是service type,就只需要加几个网络跟隐藏层连接在一起,以前已经训练好的网络不受影响(并不认同)。
在agent计算下一跳的时候,首先把整个$state$喂到DNN里面,然后计算所有的概率,最后根据目的节点和该flow选到对应的网络,再在这个网络输出的$A$个值里面采样(某一个action的值越大越容易被选中)。
状态state #
每个agent由于自己情况的不同,所对应的state space 和 action space都是不同的,DNN的结构也有些不同。
所有agent共用的部分 #
所有链路剩余容量、所有链路丢包率:由于所有链路用$|V|*|V|$的矩阵表示,所以链路剩余容量和丢包率矩阵的大小都是$|V|^2$。
agent之间不同的部分 #
每个邻居到其他节点的最大容量:这个记录了一个节点的邻居到网络中所有节点的最大容量(从一个节点到另一个节点的所有路径中,容量最大的路径的容量),大小是$|V| \cdot |N|$,其中$|N|$是这个节点邻居的数目。
每个邻居到其他节点的距离:每个邻居到所有节点的距离(跳数hop),大小$|V| \cdot |N|$
one-hot vector:包含源节点、目的节点、flow类型的one-hot。大小 $2|V|+|T|$,$|T|$是service type的数目。 (one-hot就是一个向量,其中只有一个元素是1,其他的都是0。比如一共有3个节点,我想代表2号节点,对应的向量就是$[0,0,1]$)
condition state:这是一个向量,内容要么是0,要么是1.如果某一个位置上是1,就代表之前已经有一个对应的agent被加到了path中,后文中将结合代码实现讨论。
动作action #
action space就是每个agent的邻居的数目,根据agent选择的action,把flow转发给对应的邻居。
奖励reward #
由于每种类型的需求不同,为了让DRL更好的服务不同类型的flow,需要根据类型的不同来使用不同的奖励函数。奖励函数的定义如下:
$U_t=w_1log x_t - w_2y_t^{\alpha _1}- w_3z_t^{\alpha _2}$
其中$x_t$是吞吐量,$y_t$是延时,$z_t$是丢包率。为了让这些指标到一个数量级,使用$log(\cdot)$和$(\cdot)^\alpha$来处理数据。$w$是不同指标的权重,有以下的设置。
| 服务类型 | 典型应用 | $w_1$ | $w_2$ | $w_3$ |
|---|---|---|---|---|
| latency-sensitive | 上网 | 0 | 1 | 0 |
| throughput-sensitive | 下文件 | 1 | 0 | 0 |
| latency-throughput-sensitive | 视频直播 | 0.5 | 0.5 | 0 |
| latency-loss-sensitive | 打游戏 | 0 | 0.5 | 0.5 |
PPO算法 #
在DRL-OR中,每个agent都有自己的模型,而且并不是每个agent都在规划的path上面,如果不在path上就不应该得到奖励。目标函数:
$J(\theta)^{CLIP} =\Bbb E_{\tau\sim p_{\theta^i_{old}}(\tau)}[m^i \cdot min(A(s,\textbf{a})r(\theta ^i),A(s,\textbf{a})r’(\theta ^i) )]$
如果agent在path上,${m^i}$为1,否则是0. 其中$r(\theta ^i)$是新旧两个$\pi$函数预测值的比值,是一个比值构成的向量。为了让预测更加稳定,PPO对$r(\theta ^i)$进行了裁剪得到$r’(\theta ^i)$,也就是限制在$(1-\epsilon,1+\epsilon)$之间,这样更新幅度就不会太大。$A(s,\textbf{a})$是PPO中的一个advantage fuction,跟奖励reward有关,并反映了action的好坏,详见 PPO论文.
算法实现 #
算法部分参照DRL-OR的 开源代码。
算法中包含五个主要进程。testbed、ryu-controller、drl-or、client、server。
其中drl-or是算法部分的实现,在drl-or中会根据配置生成flow的请求(包含一个flow的很多信息),然后把计算的flow发送给testbed,计算的path发送给ryu-controller。
testbed是基于
mininet的一个程序,testbed根据事先配置的拓扑结构来模拟一些host和switch。在收到生成的flow请求后,testbed会开启client进程和server进程,client进程负责按照flow的要求来向server进程按照一定的速度发送一定时间的flow。server进程负责统计实际收到的吞吐量、时延、丢包率,并在进程结束的时候返回给testbed。testbed中的switch的控制机制是在ryu-controller中实现的,每次testbed中的switch收到一个包,都要去问ryu-controller往哪儿转发,后者根据path信息,确定转发的方向。
实现细节 #
drl-or进程启动的时候回去读取拓扑配置文件,配置文件中定义了网络中的节点和链路的信息,还有任意两个节点之间的发包权重。drl-or根据这些权重来随机生成任意两个节点之间的flow(权重越高,生成的几率越高),这个flow可能是任意的service type。此时生成的flow的src,dst,type,duration(持续时间)是确定的。我们需要计算这个flow是按照怎样的路径从src到dst。
这里有一个特殊的向量condition state,它标记了哪些agent已经被加到了path之中,相当于让agent偷看到了其他agent的选择。condition state中的元素要么是0,要么是1。如果是1,就代表对应的那个agent已经被加到了path中。
从src节点开始,计算$state$,由于src是path中的第一个节点,所以src看到的condition state 是$[0,0\cdots 0]$全0的。将$state$+condition state喂给actor-critic,actor将计算出对应的action,critic也将计算出value,这个value是对奖励的预测,用在PPO算法中。
由于src确定了action,那么path中就已经有了src节点了,同时第二个节点也就确定了。同样的,也为第二个节点计算$state$和condition state,由于src已经在path中,那么第二个节点看到的condition state就是 $[0,0\cdots 0,1,0\cdots0]$,那个1对应的就是src的节点。
重复上面的步骤,直到path达到dst节点或者出现了环。要知道这个path是DRL生成的,有可能根本就是随机的,所以算法需要检查path是否合法,例如有环、超出链路剩余容量等。如果path有问题,算法就会再生成一个新的path,这个新path是按照图的方法来计算出来的。这个时候,前文中计算的节点之间的跳数还有节点之间的最大容量就被用来计算新的path。
这个时候一个flow需要的一切都准备好了,drl-or进程把flow的src,dst,src_port,dst_port,path发送给ryu-controller,ryu-controller会在交换机中进行设置,当交换机遇到这个flow的时候就会按照path的要求,往对应的节点转发。同时drl-or将src,dst,src_port,dst_port,type,demand(发送速率),time(持续时间)发送给testbed,testbed开启client进程来发送TCP包,同时开启server进程来接收TCP包。
server进程会统计包的吞吐量、时延、丢包率,并通过管道返回给testbed,server的统计结果会在运行过程中隔一段时间就返回一次,但是testbed只care一次的结果。testbed在收到统计结果后就将统计结果发送给drl-or。此后的testbed会在时间到了以后将client和server进程杀掉。所以也就是说testbed即使返回了统计结果,这个结果也只是一段时间内的统计结果,并不是最终的统计结果。而且即使返回了统计结果,client和server也是还在运行着的。
drl-or收到统计结果后,按照上文中的函数来计算奖励reward。但这个时候不会立即更新actor-critic模型,而是将所有的state,action,reward,next_state,value,condition state保存在一个replay buffer中。在一段时间以后将这个replay buffer中的数据随机(消除数据之间的相关性)取一些出来,然后交给PPO算法来学习,并更新actor-critic模型。
下图是算法实现的一些模块之间的调用关系。
