[IWQoS'21]DarkTE: Towards Dark Traffic Engineering in Data Center Networks with Ensemble Learning
Table of Contents
论文笔记 - This article is part of a series.
1 背景 #
- mice流: 通常大小只有几KB的流
- elephant流: 数据量很大,可以达到几个GB
1.1 dark routing #
不知道流大小的情况下,也能高效利用网络,并有较小的流完成时间(FCT)
1.2 传统算法 #
需要持续地检测流,当流发送到一定的数据量以后才会把流归为elephant流。而在这之前,mice 和 elephant流可能会共用已经拥塞的链路。
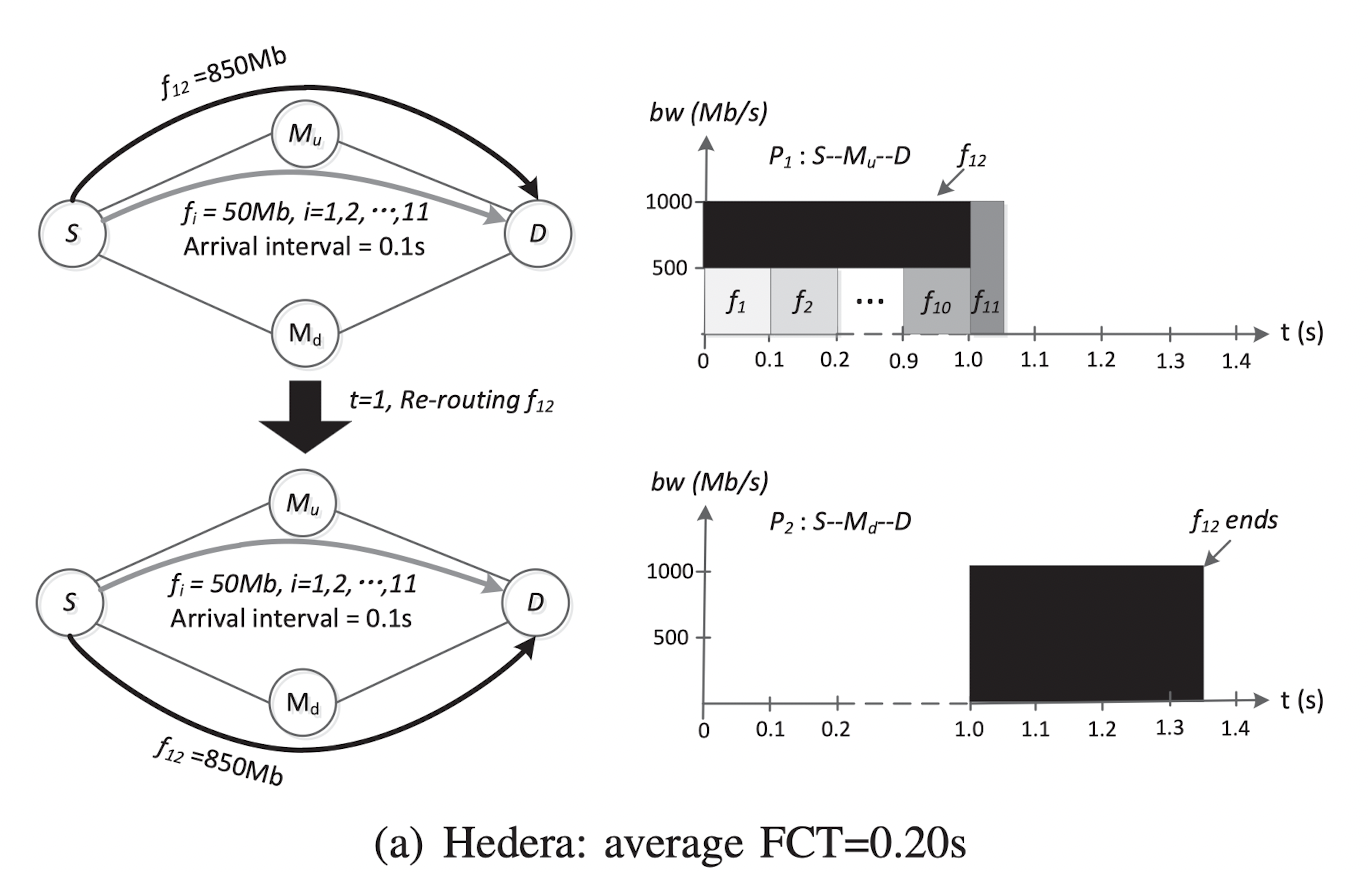
在这个例子中,有11条mice 流($f_1 \cdots f_{11}$)和一条elephant流($f_{12}$)。由于Hedera使用ECMP,流会随机的被分到一条路径上。因此$f_1$和$f_{12}$可能同时在$S\rightarrow M_u \rightarrow D$的路径上。而路径$S\rightarrow M_d \rightarrow D$则未被使用。并且在一段时间以后Hedera意识到$f_{12}$是elephant流,因此将其转移到路径$S\rightarrow M_d \rightarrow D$。这样的情况下,所有流的平均FCT为0.2秒。
如果流分类算法能在一开始就分辨出$f_{12}$是elephant,则可以将其放在下边的路径上。并且,可以将平均的FCT减少为0.12s。
但是实际上,很难一开始就判断出一条flow是elephant。
1.3 基于机器学习的算法 #
可以通过基于机器学习的算法来对flow的大小进行判断,并判断一条流是否为mice or elephant。 但是算法准确率并不能达到100%, 因此如果mice流被错误地判断为elephant流,那么就有可能导致其FCT增加。
2 设计 #
2.1 流分类 #
DarkTE使用 随机森林的方式来实现对流分类。随机森林的主要思路就是从样本中可放回地随机采样N组样本(样本可以重复),然后根据每组样本生成一个决策树。这样最后就会得到N个决策树。并且每个决策树只使用其中的一些feature来进行决策。(DarkTE中,这些feature就是数据集中关于flow的一些数据。由于使用机器学习类算法,因此也不关注feature实际的含义)
例如决策树1,使用tcp queue 和 agg net in作为判断的feature。那么决策树2就可能使用agg net out 和 first call 作为feature。
然后将flow放入N个决策树进行分类,每个决策树会根据这个flow的一些feature来预测这个flow的size。
对于随机森林分类的结果,可以根据阈值的设定来将流分成mice 或者是elephant。 如果是被分成了Mice流,那么就采用ECMP的方式,将这个flow随机分到一条路径上。 如果是elephant流,则会继续后面的流程通过启发式来调整这条流的速率。
confidence score #
由于每个决策树都有一个预测值,有的高有的低。那么最大的预测值就是upper bound,最小的预测值就是lower bound。
$$variance=\frac{upper bound - lower bound}{prediction flow size}$$ $$confidence score = 1 - variance$$
可以看到如果upper bound 和lower bound的差距越大,也就是说不同决策树预测的流大小差距越大,则说明对预测结果不准确,那么confidence就会很低。(不是很清楚分母的prediction flow size是什么意思,感觉换成upper bound也说得过去)
2.2 速率分配 #
DarkTE中,通过测量flow的速率(rate),然后将elephant流的速率进行调整来优化网络。后文中,通过测得的flow rate和随机森林预测的confidence score来对flow rate进行调整。
DarkTE-D #

DarkTE-D算法的目的就是不断地调用RATE-SRC (step 8)和RATE-DST (step 11),在起点和终点对flow的速率调整,直到调整收敛。
RATE-SRC #

RATE-SRC是在源点对流进行调整。对于已收敛的flow,不再调整其速率,只是把其的速率加起来(step 5)来确定节点的剩余带宽。未收敛的flow,则将confidence加起来(step 6)。然后在step 11的时候(我认为不应该是1.0,而应该是节点的出口带宽),对于那些未收敛的flow,按照其confidence来将为分配的出口带宽进行分配。
不过这样的分配只是让flow的速率和confidence成正比,只是满足了源节点的出口带宽,但可能超出了目标节点的带宽。
RATE-DST #

RATE-DST 在目的节点对flow rate进行调整。
step 16-19进行初始化,对所有目的节点为该节点的流的confidence和速率进行统计。
step 21-22则是判断进来的flow是否会占用完所有的带宽,如果占用不完,就不再调整了。(这一步也有问题,不应该是1.0,而是带宽)
step27-29在判断一个flow需求的带宽如果小于如果按照跟confidence正比的方式可以为它分配的带宽,那么就直接把这部分带宽分给这个流。($d_S$是已经分配了的带宽,$S_C$是所有还没分配带宽的流的confidence 总和)
step 30-31 如果暂时还不能确定分配,就先记录为确定的flow的confidence的和,这样后续的步骤就能继续分配。
step 36-38 则是对那些是实在无法满足其带宽需求的flow(这些flow的要的速率太大,confidence又太小,导致无法通过step 27的判断),则按照其confidence的比例将剩下的带宽进行分配。
速率分配总结 #
可以看出,DarkTE首先通过随机森林的方式来估计一个流需要的速率(rate),并给出确定的程度(confidence score)。然后根据这两个值,根据flow的源节点和目的节点的流的情况来调整实际分配给flow的速率。认真细看代码,可以发现,实际上是step 27先根据随机森林预测的流大小进行分配。实在不行才按照confidence的大小来分配。
实际分配的速率有以下特点:
- 节点的流的速率只和不会超过节点的带宽。
- confidence越大,能分到的速率也就越多
2.3 路径选择 #
在一般的方法中,路径选择按照first-hit的原则。以找到的第一条路径作为使用的路径,并且先到的flow先选择路径。并且在选择路径的时候,总选择容量最大的路径。
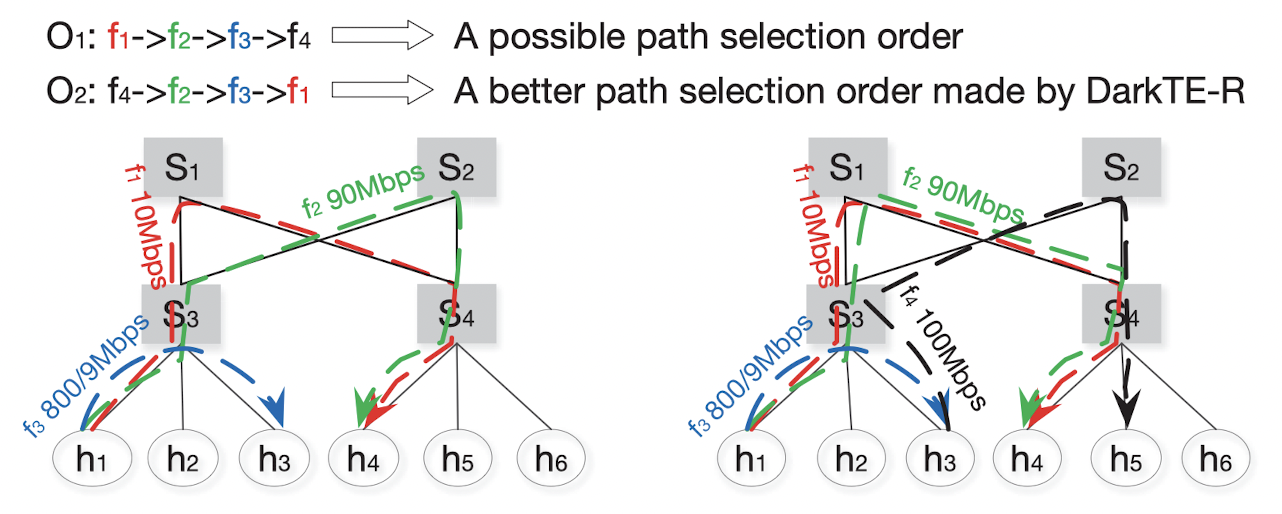
但是在某些情况下,可能导致有些流无法被分配。如左图中,flow按照$O_1$的次序,并且每条链路的容量是100Mbps。那么就会导致$f_4$因为链路容量不够而无法被分配。
所以作者提出highest-confidence-first(HCF)的方法来安排流搜索路径的顺序。实际上就是先按照confidence score把流排序一次。然后按照排序后的次序来作为到达次序,先给confidence大的flow分配路径,再给小的分配。
其实质上,是因为有些mice流被误判为elephant,从而会为他们分配很高的速率并导致带宽的浪费。所以要先给confidence高的流分配,这样来减少浪费。